前言
为什么我们使用 chatgpt 问一个问题,回答时,他是一个字或者一个词一个词的蹦出来,感觉是有个人在输入,显得很高级,其实这这一个词一个词蹦不是为了高级感,而是他的实现原理决定的,下面我们看下为什么是一个一个蹦出来的
大模型的本质
特斯拉前 AI 总监 Andrej Karpathy 将大语言模型简单的描述为: 大模型的本质就是两个文件,一个是参数文件,一个是包含运行这些参数的代码文件。
参数文件是组成整个神经网络的权重,代码文件是用来运行这个神经网络的代码,可以是 C 或者其他任何编程语言写的,当然目前主要都是 Python。
那么接下来的问题就是:参数从哪里来?
这就引到了模型训练。
本质上来说,大模型训练就是对互联网数据进行有损压缩(大约 10TB 文本),需要一个巨大的 GPU 集群来完成。
以 700 亿参数的 Llama 2 (Facebook 开源的羊驼大模型) 为例,就需要 6000 块 GPU,然后花上 12 天得到一个大约 140GB 的 “压缩文件”,整个过程耗费大约 200 万美元。
而有了 “压缩文件”,模型就等于靠这些数据对世界形成了理解。

大模型是如何工作的
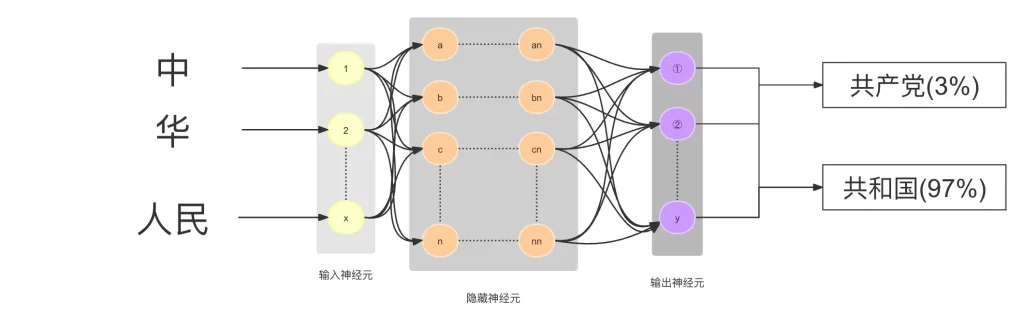
简单来说,大模型的工作原理就是依靠这些压缩数据的神经网络对所给序列中的下一个单词进行预测。
比如我们问将 “中 华 人民 ” 输入进去后,请大模型补充完整,可以想象是分散在整个网络中的十亿、上百亿参数依靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如 “共和国(97%)”,就形成了 “中华人民共和国” 的完整句子。然后继续将 “中华人民共和国” 作为输入,继续依・靠神经元相互连接,顺着这种连接就找到了下一个连接的词,然后给出概率,比如 “中华人民共和国 成立于 1949 年(98%)”。


u395xy